 Learn different aspects of CAP theorem or Brewer’s theorem for choosing databases, history of CAP theorem, basic use case of CAP theorem. CAP: Consistency, Availability, and Partition tolerance in database.
Learn different aspects of CAP theorem or Brewer’s theorem for choosing databases, history of CAP theorem, basic use case of CAP theorem. CAP: Consistency, Availability, and Partition tolerance in database.
1. Overview of CAP Theorem
CAP theorem or Brewer’s theorem states, says you have option to pick only 2 at any point in time out of three: C, A or P.
Here, you can find meaning of each character in CAP theorem.
- C stand for Consistency
- A stand for Availability and
- P stand for Partition Tolerance.
2. History of CAP Theorem
The CAP theorem, also known as Brewer’s theorem after computer scientist Eric Brewer, states that it is impossible for a distributed computer system to simultaneously provide all three (C, A , P ) guarantees.
Eric Brewer, the theorem first appeared in 1998. In 2012, Brewer clarified some of his positions, including why the often-used “two out of three”
3. Basic of CAP Theorem
I try to explain in a basic way, what is the meaning of each three-term here.
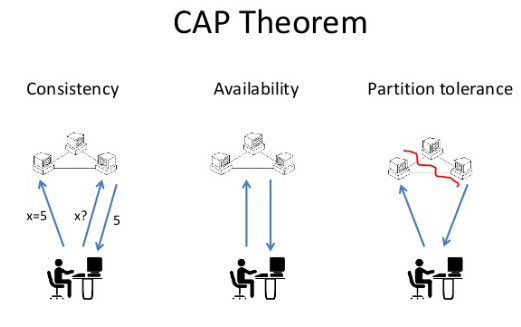
3.1 Consistency
All client has same view of data irrespective of delete or update .
3.2 Availability
Each client can always read and write.
Availability can be achieved from distributed system with some cost. How much cost is acceptable for your business trade-off, based on this you can make your system available , if you want to know about the Availability of system you can read this post.
3.3 Partition tolerance
All system works well despite of physical network partitioned.
The meaning of above is, system continues to operate as expected even with node failure. In the above quotes, network partitioned means , it could partitioned in two one part is group of working node and another part may be a group of breakdown nodes.
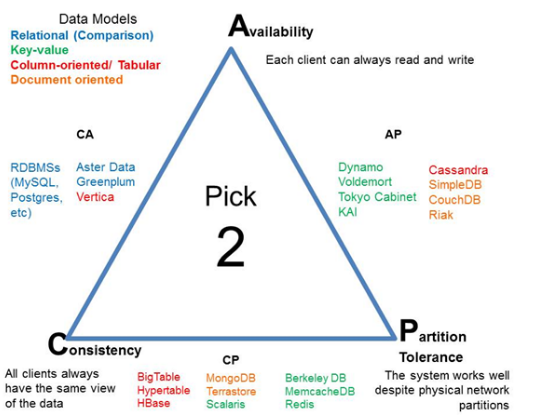
4. Triangular View of CAP Theorem
5. Use case to choose 2 out of three C.A.P. Theorem
The equilateral triangle view of the CAP theorem explained a lot of high-level things.
- CA (Consistency and Availability) : CA says: Single site cluster, therefore all nodes are always in contact, when a partition occurs, the system blocks. Choose C and A with compromising of P (Partition Tolerance). e.g. type of applications: Banking and Finance application, a system which must have transaction e.g. connected to RDBMS.
- AP ( Availability and Partition Tolerance): AP says: System is still available under partitioning, but some of the data returned may be inaccurate. Choose A and P with compromising of C (Consistency). When to choose AP to achieve what is itself a question. There is a use case: return the most recent version of the data you have, which could be stale. This system state will also accept writes that can be processed later when the partition is resolved. Availability is also a compelling option when the system needs to continue to function in spite of external errors. Type of applications: shopping carts, any consumer-facing system, News publishing CMS ( e.g. times of India news site), etc. Sometimes architects choose eventual consistency with compromising Availability or Partition tolerance to some extent.
- CP (Consistency and Partition Tolerance): CP says some data may not be accessible, but the rest is still consistent/accurate. choose based on the requirement analysis. for example: Cassandra, Amazon’s DynamoDB, Voldemort, Riak, SimpleDB etc.
6. When to Opt What ?
In a nutshell, the following are the key points that may guide when to choose what. When to choose what is sometimes very difficult but most of the time. In all the three, first out of three is very clear, only second one out of three have to choose very carefully and that must be chosen cleverly based on the experience that you have.
- choose Consistency over Availability when your business requirements dictate atomic reads and writes.
- choose Availability over Consistency when business requirements allow for some flexibility, to synchronizes data with some acceptable delay ( or when network failed restored in working mode).
- The choosing between Consistency and Availability is a software trade-off.
- In any business requirement, you must have first one of three i.e. primary out of (C, A, and P), but second should be chosen carefully
5. Conclusion of Brewer’s Theorem
As an architect, the control is in your hands, choose what to do for facing a network partition. Network failure is obvious, don’t assume the network will not fail, assume it will fail when. Network outages can be either short duration or long duration, it can be in different things.
Building distributed systems provide many advantages, but also adds complexity. Understanding the trade-offs available to you, for facing network errors, and choosing the right path is crucial to the success of your application.
In a nutshell, first of all analyse the requirements of your application, database, NFR and ask possible question to yourself, few of them as:
- do you required Linear Scalability?
- what type of data you have?
- What extends of Data Loss is acceptable?
- No downtime?
- No Data loss?
- Performance under workload (irrespective of read heavy, write heavy , read-write heavy)?
- How much Consistency you required?
- Which philosophy you choose either ACID or BASE?
- another requirements…. etc
6. Reference
Wiki
I hope you enjoyed this post of Brewer’s theorem or CAP theorem, it history , its use case, when to choose what etc, and you can visit tutorial listing page for more blog post.
Please write your comment or suggestion, if you like this post.
Pingback: Anna
this is it which I’m looking for last 2 days… greatestuff
Pingback: Kriti
Pingback: Rakhi
Cassandra, Amazon’s DynamoDB, Voldemort, Riak, simpleDB are marked as “AP” in the image and as “CP” in text below…
excellent publish, very informative. I’m wondering why
the other experts of this sector don’t understand this.
You must proceed your writing. I am sure, you have a huge readers’ base already!
Definitely, what a great blog and revealing posts, I definitely will bookmark your site. Best Regards!
I reckon something truly special in this website.